EmotionalAI
Multimodal Emotion Analysis & Video Generation
When we watch a movie, we instantly know when a character is hiding their true feelings. But how do we know? We're processing facial expressions, vocal tone, dialogue content, and our memory of what happened — all simultaneously, unconsciously. Can AI do the same?
Where is the AI?
No single AI model can simultaneously see faces, hear voices, read text, and remember what happened 30 minutes ago. DeepFace only sees. WhisperX only hears. Wav2Vec2 only feels tone. Our AI is not in any single model — it's in the architecture. The intelligence emerges from how signals are fused, how conflicts between modalities reveal suppressed emotions, how memories accumulate across scenes, and how all of this becomes actionable video prompts. Like the brain: no single neuron is intelligent, but billions connected together produce understanding.
Four Cognitive Layers
1
Perception — See, Hear, Read
Extract raw emotional signals from every frame
The system watches the movie frame by frame. For every face that appears, it detects the identity and reads the emotion. For every line spoken, it first separates vocals from background music (Demucs), reduces noise (DeepFilterNet), then transcribes every word with millisecond-precision timestamps (WhisperX). It identifies who is speaking (pyannote diarization) and measures their vocal emotion — arousal, valence, dominance (Wav2Vec2 SER). The transcribed text is then run through DistilRoBERTa emotion classification to get a text-level emotion label and confidence score — a third independent signal alongside face and voice. Three channels, each telling a potentially different story about the same moment.
Three Perception Channels
Visual (FER)
RetinaFace detection
Facenet512 recognition
DeepFace emotion
Facenet512 recognition
DeepFace emotion
Audio (SER + ASR)
WhisperX transcript
Wav2Vec2 arousal
valence & dominance
Wav2Vec2 arousal
valence & dominance
Text (NLP)
DistilRoBERTa 7-class
emotion + confidence score
anger/joy/sadness/fear/surprise/disgust/neutral
emotion + confidence score
anger/joy/sadness/fear/surprise/disgust/neutral
character,dialogue,text_emotion,audio_arousal,audio_valence,face_emotion
Brent,"Why do we care if we were expelled?",anger,0.762,0.649,neutral
Scarlett,"Wearing as if I waited for the poor...",anger,0.814,-0.312,happy ← CONFLICT
"Sees Scarlett smiling (happy, confidence 85%), hears her voice cracking (arousal 0.82, valence -0.31), reads dialogue tagged as sadness. Three signals — three different answers."
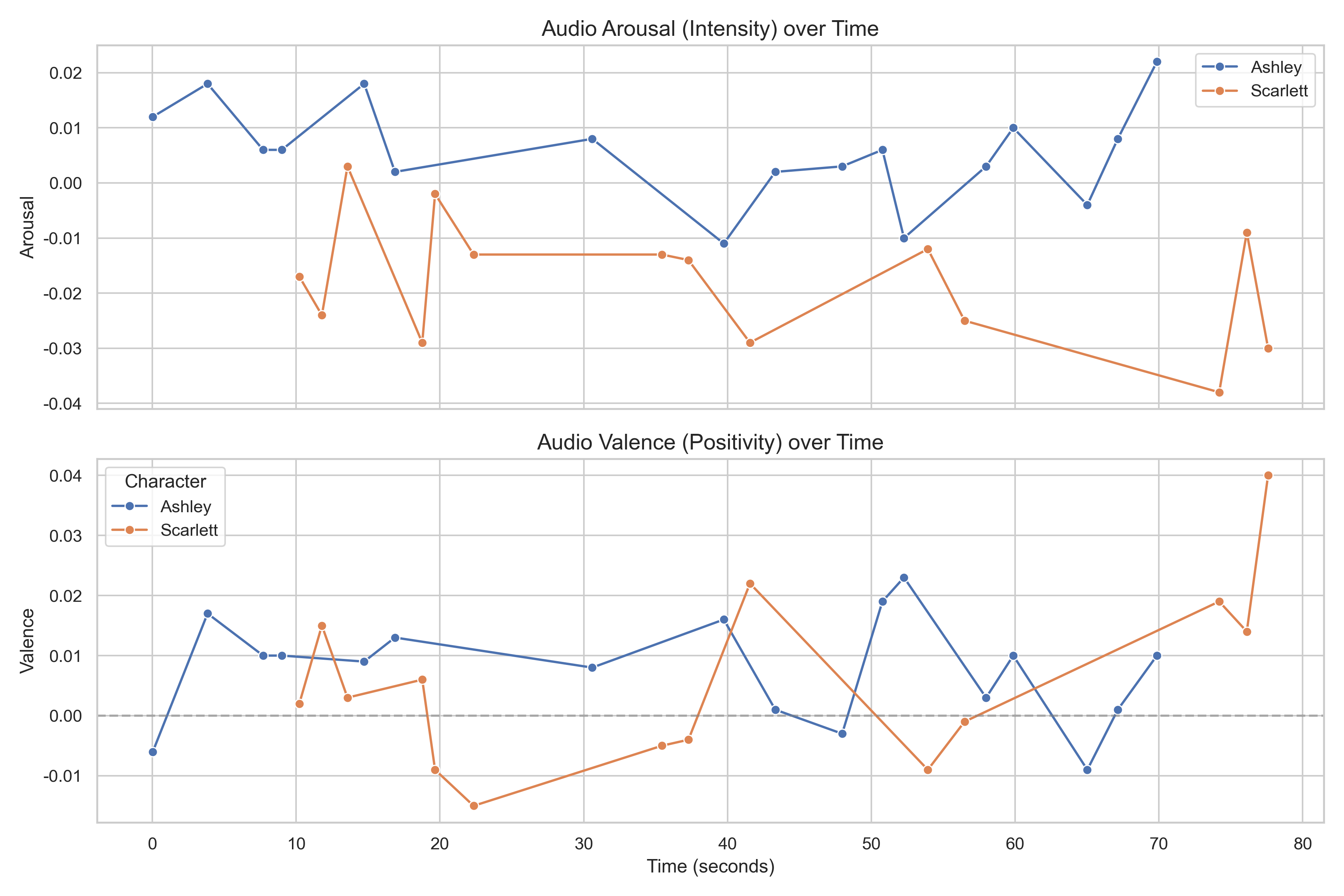
Arousal and valence across the entire movie timeline — automatically extracted by the pipeline
2
Memory — Remember Every Character's Journey
Context transforms raw data into meaning
A smile means nothing without context. Is she genuinely happy, or masking pain? The only way to know is to remember what happened before. Our system maintains two layers of memory for each character: short-term memory tracks the current scene (sliding window of recent events), while long-term memory spans the entire film (stored in ChromaDB vector database). When something surprising happens — measured by an LSTM model — it gets promoted from short-term to long-term storage.
Three-Tier Memory Architecture
STM (deque, window=5) → when LSTM surprise > threshold → Candidate Buffer
↓
reference count ≥ 2
↓
Long-Term Memory (ChromaDB)
↓
Semantic retrieval for future scenes
STM:
Candidate Buffer: Memories that were surprising but not yet confirmed important
LTM: ChromaDB persistent vector store — semantic similarity retrieval, emotion-boosted search
Promotion: LSTM surprise score detects unexpected emotion transitions; reference counting confirms importance
deque(maxlen=5) per character — recent emotions, trends, volatilityCandidate Buffer: Memories that were surprising but not yet confirmed important
LTM: ChromaDB persistent vector store — semantic similarity retrieval, emotion-boosted search
Promotion: LSTM surprise score detects unexpected emotion transitions; reference counting confirms importance
"Retrieves: Rhett walked out 2 minutes ago (LTM). Cross-references: this is her 3rd rejection across the film — a behavioral pattern emerges. Her current smile is inconsistent with her history."
3
Understanding — Judge the Truth Behind the Mask
Perception + Memory = Character insight
This is where perception and memory merge into understanding. When the face says happy, the voice says distressed, and the text says sad — that's not noise, that's a signal. The system classifies this as an emotional conflict, indicating possible suppression. It also builds long-term character models: Big-5 personality traits (OCEAN) drive predicted behavior baselines; Dunbar social circles map relationship intimacy; and a 6-dimension scoring engine evaluates acting performance with transparent, reproducible formulas.
Analysis Modules
Emotion State Machine
NATURAL / GRADUAL
TRIGGERED / SUDDEN
LSTM surprise detection
TRIGGERED / SUDDEN
LSTM surprise detection
Conflict Detection
face ≠ voice ≠ text
→ suppression signal
polarity-based rules
→ suppression signal
polarity-based rules
Scoring Engine
6 dimensions, white-box
FER degradation tiers
circumplex distance
FER degradation tiers
circumplex distance
Scene: Scarlett says "I will think about it tomorrow"
───────────────────────────────────────────────────
Visual (FER): happy (confidence 0.85) → POSITIVE
Audio (SER): arousal 0.82, valence -0.31 → NEGATIVE
Text (NLP): sadness (score 0.71) → NEGATIVE
⚠ MULTIMODAL CONFLICT: 2/3 channels disagree on polarity
→ Transition type: TRIGGERED (LSTM surprise: 0.78)
→ Interpretation: suppressed grief masked by social smile
"All analysis is deterministic algorithms — no LLM reasoning. The LLM (Qwen2.5) only renders structured data into natural language. This ensures every run produces the same result."
Open interactive analysis dashboard (4.9MB) →
4
Creation — Generate What the System Understood
Analysis becomes actionable video prompts
The final layer transforms analysis into action. The system generates a 6-dimension prompt for each key scene: expression, body language, atmosphere, camera, composition, and dialogue action. Pipeline data is the primary driver — emotion labels, arousal/valence, and Dunbar circles directly determine every dimension. Screenplay stage directions serve only as supplementary reference for physical actions that sensors cannot capture (e.g., "walks toward the door"). Three of six dimensions are 100% pipeline-driven with no screenplay input at all. Without the screenplay, the system still works — our ablation experiment shows pipeline-only prompts produce coherent videos, just with less scene detail. The video output is proof that our pipeline analysis is specific enough to be actionable.
6-Dimension Prompt Structure
Dim 1 (Expression): jaw clenched, brow furrowed, nostrils flaring, lips pressed
Dim 2 (Body): high-energy, assertive posture
Dim 3 (Atmosphere): sunlit parlor, warm afternoon light, tense
Dim 4 (Composition): intimate two-shot (Dunbar circle: inner)
Dim 5 (Camera): close-up, eye-level, static hold
Dim 6 (Action): speaks firmly, "How proud of yourself you are!"
→ LTX-Video 2.3: "A close-up of a young woman in a 1939 Hollywood drama
filmed in rich Technicolor. Her jaw tightens and nostrils flare as she
faces the man before her. She speaks firmly, 'How proud of yourself
you are!' The camera holds steady on her face."
"Every word traces to either pipeline data or screenplay text — zero fabrication. Our experiment showed: physical cues ('jaw tightens') outperform abstract labels ('angry expression') by 66% in generated video quality."
Explore Further