EmotionalAI System Showcase
Four Modules — From Raw Video to Generated Scene
29,728 lines of code
1,796 tests passing
187 experiment clips
739 memories stored
1,375 screenplay scenes
1. Pipeline
2. Cognitive
3. Prompt Engine
4. Video Generation
5. Results
6. Micro-Expression
Module 1: Multimodal Perception Pipeline (3,241 lines)
Four sequential stages extract emotional signals from raw video. Each stage runs in its own conda environment (TensorFlow for visual, PyTorch for audio) to avoid dependency conflicts. Output: one CSV row per utterance with 14 columns covering all three modalities.
Stage 1: Visual — Face Detection + Recognition + Emotion
Process video frame-by-frame (every 0.25s). Detect faces, identify who they are, classify their emotion. Optimized for old movies with GFPGAN restoration.
RetinaFace
Face detection
Confidence threshold: 0.9
Auto-downscale for HD (6-7x speedup)
Confidence threshold: 0.9
Auto-downscale for HD (6-7x speedup)
Facenet512 / ArcFace
Face recognition
Vectorized cosine distance
Batch matching (entire DB)
Vectorized cosine distance
Batch matching (entire DB)
DeepFace
7-class emotion
angry/disgust/fear/happy/neutral/sad/surprise
+ confidence score
angry/disgust/fear/happy/neutral/sad/surprise
+ confidence score
Old Movie Mode
GFPGAN 2x/4x upscale
CLAHE B&W enhancement
Face quality scoring
CLAHE B&W enhancement
Face quality scoring
OUTPUT — final_women.csv (1,901 rows for GWTW Part 1)
| person | emotion | file | confidence |
|---|---|---|---|
| 1_woman | happy | 374.75.jpg | 0.85 |
| 1_woman | sad | 571.82.jpg | 1.00 |
| 3_woman | neutral | 822.28.jpg | 0.67 |
Stage 2: Audio — Enhancement + Transcription + Speaker ID
Six-phase audio pipeline: vocal separation, noise reduction, transcription, word-level alignment, hallucination filtering, speaker diarization.
Demucs (Meta)
Music/vocal separation
Removes background score
Critical for old movies
Removes background score
Critical for old movies
DeepFilterNet
Noise reduction
Removes tape hiss, crackle
White noise suppression
Removes tape hiss, crackle
White noise suppression
WhisperX (large-v3)
ASR + wav2vec2 alignment
Word-level timestamps (ms)
Batch size: 8
Word-level timestamps (ms)
Batch size: 8
Hallucination Filter
logprob < -1.0 (gibberish)
compression > 2.4 (repetitive)
no_speech > 0.6 (silence)
compression > 2.4 (repetitive)
no_speech > 0.6 (silence)
pyannote
Speaker diarization
2-5 speakers detected
Voice profile matching
2-5 speakers detected
Voice profile matching
DistilRoBERTa
Text emotion (7-class)
j-hartmann model
emotion + confidence score
j-hartmann model
emotion + confidence score
Stage 3: Speech Emotion Recognition
Wav2Vec2 predicts continuous emotion dimensions from raw audio: arousal (calm→excited), valence (negative→positive), dominance (submissive→assertive).
Wav2Vec2 (audeering)
3D emotion regression
arousal / valence / dominance
Adaptive batching (64→1)
arousal / valence / dominance
Adaptive batching (64→1)
Degradation Detection
If arousal range < 0.2
→ auto-disable SER channel
Common in old movie audio
→ auto-disable SER channel
Common in old movie audio
Stage 4: Multimodal Fusion
Align three timelines into one dataset. Auto-detect FER timestamp offsets. Match faces to speech with 3-window strategy (before/during/after). Detect listener reactions.
FER Offset Detection
If FER min > transcript max + 60s
→ auto-correct offset
Handles clipped video timestamps
→ auto-correct offset
Handles clipped video timestamps
3-Window Matching
before (1.5s) + during + after (1.5s)
Binary search O(n log m)
np.searchsorted vectorized
Binary search O(n log m)
np.searchsorted vectorized
Listener Detection
Find non-speaker faces
in same time window
→ reaction shot analysis
in same time window
→ reaction shot analysis
Conflict Detection
face ≠ voice ≠ text polarity
→ emotional suppression signal
2/3 channels disagree = CONFLICT
→ emotional suppression signal
2/3 channels disagree = CONFLICT
OUTPUT — multimodal_dataset.csv (1,544 rows, 14 columns)
| character | dialogue | text_emo | arousal | valence | face | listener |
|---|---|---|---|---|---|---|
| Scarlett | "Wearing as if I waited..." | anger | 0.814 | -0.312 | happy ⚠ | 24_man |
| Gerald | "It's no use, Pa..." | sad | 0.413 | -0.158 | sad | — |
| Mammy | "Miss Scarlett!" | anger | 0.891 | 0.234 | angry | 1_woman |
⚠ Scarlett: text=anger, voice=negative, but face=happy → MULTIMODAL CONFLICT
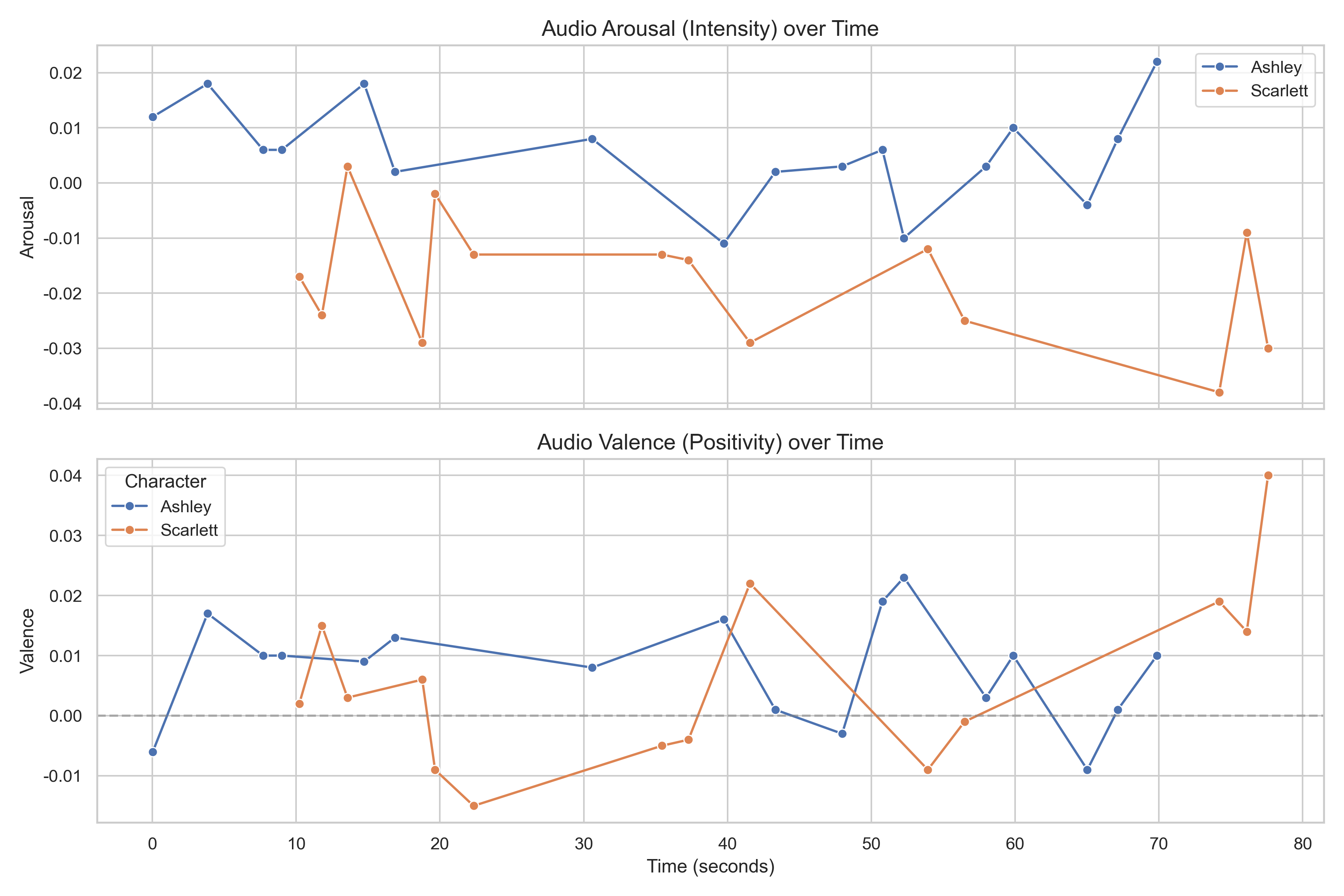
Arousal and valence across GWTW HD — automatically extracted by the pipeline
Module 2: Cognitive Analysis Engine (13,568 lines)
Five steps transform raw pipeline data into character understanding. All analysis is deterministic algorithms — the LLM (Qwen2.5) only renders data into prose, never makes analytical decisions.
Step 1: Data Bridge — Pipeline CSV → SceneAnalysis
PipelineBridge loads FER/SER/transcript CSVs, aligns timestamps, applies content-adaptive weights (old movie: Text 40%, FER 35%, SER 10%), and outputs canonical SceneAnalysis objects.
Step 2: Core Analysis — Emotion Arcs + Timeline
EmotionArc
Arc classification: RISING / FALLING / PEAK / VALLEY / W_SHAPE / FLAT / VOLATILE
Smoothed via numpy convolution
Turning point detection (threshold: 0.3 valence change)
Smoothed via numpy convolution
Turning point detection (threshold: 0.3 valence change)
MoodTracker
Mid-term mood state
Exponential decay toward baseline
Biases perception (emotional noise effect)
Exponential decay toward baseline
Biases perception (emotional noise effect)
Step 3: Cognitive Memory — The Core Innovation
Five interconnected sub-modules implement a psychology-grounded memory architecture: emotion tracking, short-term buffer, long-term storage, memory consolidation, and scene boundary detection.
Emotion State Machine (486 lines)
4 transition types: NATURAL / GRADUAL / TRIGGERED / SUDDEN
LSTM surprise: 2-layer LSTM predicts next (valence, arousal); MSE = surprise score
OCEAN modulation: high neuroticism lowers stability baseline
Theory of Mind: LLM explains high-surprise transitions
LSTM surprise: 2-layer LSTM predicts next (valence, arousal); MSE = surprise score
OCEAN modulation: high neuroticism lowers stability baseline
Theory of Mind: LLM explains high-surprise transitions
Short-Term Memory (279 lines)
Sliding window: deque(maxlen=5) per character
Trend detection: IMPROVING / DECLINING / STABLE / VOLATILE
Social pressure: lowers volatility threshold
Volatility: numpy std of recent valences
Trend detection: IMPROVING / DECLINING / STABLE / VOLATILE
Social pressure: lowers volatility threshold
Volatility: numpy std of recent valences
Memory Store (447 lines)
ChromaDB 3-tier: STM → Candidate → LTM
Emotion-boosted search: +0.15 if emotion matches query
Reference counting: refs ≥ 2 → promote to LTM
739 memories stored for GWTW HD
Emotion-boosted search: +0.15 if emotion matches query
Reference counting: refs ≥ 2 → promote to LTM
739 memories stored for GWTW HD
Consolidator (279 lines)
Sudden shift clustering: group by "anger → sad" patterns
Trauma hotspot detection: temporal density (3+ shifts in 60s window)
LLM summary: hard-constrained to data facts only
Memory persistence: hotspots → direct LTM
Trauma hotspot detection: temporal density (3+ shifts in 60s window)
LLM summary: hard-constrained to data facts only
Memory persistence: hotspots → direct LTM
Reflection System (660 lines)
Scene boundary: gap > 20s → archive STM, preserve high-arousal
Generative Agents: Park et al. 2023 style insight generation
Character evolution: structured 5-section narrative analysis
Hallucination guard: character name validation + empty section retry
Generative Agents: Park et al. 2023 style insight generation
Character evolution: structured 5-section narrative analysis
Hallucination guard: character name validation + empty section retry
MEMORY ARCHITECTURE
STM
deque(5) per char
Recent emotions
Recent emotions
→
LSTM Surprise
> threshold?
→
Candidate
Awaiting confirmation
→
refs ≥ 2?
Rehearsal effect
→
LTM
ChromaDB (739)
Semantic retrieval
Semantic retrieval
Step 4: Social Ecology — Personality + Relationships
OCEAN Personality (227 lines)
Auto-inferred from pipeline data:
O: emotion variety + surprise frequency
C: stability recovery + volatility + arousal control
E: mean arousal + expression density
A: pos/neg emotion ratio + social polarity + dominance
N: stability floor + sudden shift density + hotspots
Scarlett: O=0.69 C=0.48 E=0.79 A=0.41 N=0.72
Rhett: O=0.68 C=0.57 E=0.72 A=0.36 N=0.67
O: emotion variety + surprise frequency
C: stability recovery + volatility + arousal control
E: mean arousal + expression density
A: pos/neg emotion ratio + social polarity + dominance
N: stability floor + sudden shift density + hotspots
Scarlett: O=0.69 C=0.48 E=0.79 A=0.41 N=0.72
Rhett: O=0.68 C=0.57 E=0.72 A=0.36 N=0.67
Dunbar Circles (350 lines)
5 circles: Intimate(5) → Close(15) → Friends(50) → Acquaintance(150) → Stranger
Asymmetric: A→B ≠ B→A (directed relationships)
Continuous intimacy: 0.0-1.0, not discrete
Migration logging: tracks circle changes with triggers
Time decay: 0.005/min without interaction
Asymmetric: A→B ≠ B→A (directed relationships)
Continuous intimacy: 0.0-1.0, not discrete
Migration logging: tracks circle changes with triggers
Time decay: 0.005/min without interaction
Relationship Influence (655 lines)
Closeness amplification: Intimate 3x, Close 2x, Friends 1.3x
Major event detection: regex for betrayal (3x), sacrifice (3x), confession (2.5x)
Bilingual patterns: English + Chinese
Cumulative memory: positive/negative interaction tracking
Major event detection: regex for betrayal (3x), sacrifice (3x), confession (2.5x)
Bilingual patterns: English + Chinese
Cumulative memory: positive/negative interaction tracking
Step 5: Narrative Review — Scoring + AI Film Review
Scoring Engine (782 lines)
6 white-box dimensions:
1. Expression-Text consistency: 10 - |visual_v - text_v| × 5
2. Voice authenticity: circumplex Euclidean distance
3. Multimodal coherence: polarity disagreement penalty
4. Emotion range: unique/max × 10 + log(n) bonus
5. Emotion transition: 10 - avg_jump × 5
6. Interaction quality: empathy matches / total × 7 + 3
FER tiers: reliable → partial → degraded (auto-detected, adjusts weights)
1. Expression-Text consistency: 10 - |visual_v - text_v| × 5
2. Voice authenticity: circumplex Euclidean distance
3. Multimodal coherence: polarity disagreement penalty
4. Emotion range: unique/max × 10 + log(n) bonus
5. Emotion transition: 10 - avg_jump × 5
6. Interaction quality: empathy matches / total × 7 + 3
FER tiers: reliable → partial → degraded (auto-detected, adjusts weights)
Structured Report (825 lines)
Zero LLM dependency
100% reproducible: same data = same report
10 sections: emotion stats, OCEAN, scoring, timeline, memory stats, social matrix
Pure numerical + algorithmic output
100% reproducible: same data = same report
10 sections: emotion stats, OCEAN, scoring, timeline, memory stats, social matrix
Pure numerical + algorithmic output
Movie Reviewer (633 lines)
6-chapter AI film review
Character + era + relationship + arc + scoring + script analysis
LLM renders structured data → literary critique
Character + era + relationship + arc + scoring + script analysis
LLM renders structured data → literary critique
ACTUAL OUTPUT — Scarlett O'Hara Performance Score: 8.4/10
| Dimension | Score | Weight | Detail |
|---|---|---|---|
| Expression-Text Consistency | 7.6 | 18% | Based on 650 lines [FER partial, reduced weight] |
| Voice Authenticity | 6.1 | 25% | 338 climactic scenes weighted 1.5× |
| Multimodal Coherence | 8.7 | 15% | 0/650 modal conflicts detected |
| Emotion Range | 10.0 | 20% | 7 distinct emotions: sad, neutral, fear, angry, happy, surprise, disgust |
| Emotion Transition | 10.0 | 22% | Natural flow, 113 scene cuts excluded from evaluation |
Scarlett psych summary (auto-generated)
情感波動較大,從平靜轉為憤怒最常見(68次)。平均穩定性較低,突兀轉變比例 33.1%。
Social graph — Scarlett's inner circle
Intimate circle: Rhett, Melanie, Mammy | 101 nodes, 10,100 links, 25,840 migrations tracked
Module 3: Prompt Engine — Pipeline Data → 6-Dimension Prompts
Zero fabrication policy: every word traces to pipeline data or screenplay stage directions. Pipeline is the primary driver — screenplay supplements only physical actions sensors cannot capture. 3 of 6 dimensions are 100% pipeline-driven.
6-Dimension Prompt Structure
Dim 1 (Expression): pipeline FER emotion + SER arousal → intensity tier → physical cues
"jaw clenched, brow furrowed" ← anger + arousal=0.82
+ screenplay supplement if fuzzy-matched (threshold 0.6)
Dim 2 (Body Language): SER arousal + dominance → posture descriptor
arousal > 0.7 + dominance > 0.6 → "high-energy, assertive"
word count modifier: ≤5 words → brief, >25 → animated
Dim 3 (Atmosphere): pipeline valence × arousal → mood + lighting + color tone
valence < -0.1 + arousal > 0.6 → "tense, high contrast, cool lighting"
+ screenplay ENVIRONMENT_DETAILS if matched
Dim 4 (Composition): Dunbar circle → spatial rule [100% pipeline]
INTIMATE → "intimate two-shot"
STRANGER → "wide shot, at frame edges"
Dim 5 (Camera): arousal → shot scale + movement [100% pipeline]
arousal > 0.85 → EXTREME_CLOSEUP + FAST_ZOOM_IN
LSTM surprise > 0.7 → DUTCH_ANGLE override
Dim 6 (Dialogue Action): transcript regex extraction [100% pipeline]
18 bilingual patterns: confrontation, pleading, solemn, defiant...
Sub-Modules
ScreenplayProvider (1,375 scenes)
DeepSeek-OCR + Qwen2.5 extraction
Fuzzy matching (SequenceMatcher, 0.6 threshold)
Speaker verification + misattribution guard
Hit rate: 90-95% on GWTW
Fuzzy matching (SequenceMatcher, 0.6 threshold)
Speaker verification + misattribution guard
Hit rate: 90-95% on GWTW
KeyframeSelector
SUDDEN transition: +2.0 score
LSTM surprise > 0.6: include
Dialogue dramatic scoring (18 regex patterns)
Trivial filter: "yes", "ok", "hello" excluded
Max 3 keyframes/chapter
LSTM surprise > 0.6: include
Dialogue dramatic scoring (18 regex patterns)
Trivial filter: "yes", "ok", "hello" excluded
Max 3 keyframes/chapter
De-Duplication
Track last screenplay text per dimension
If repeat → fallback to pipeline data
Prevents consecutive identical prompts
Atmosphere: regenerate from valence×arousal
If repeat → fallback to pipeline data
Prevents consecutive identical prompts
Atmosphere: regenerate from valence×arousal
Character Anchor
Visual consistency prefix
Knowledge base: 12 character descriptions
OCEAN traits as personality cues
Reused across all frames for same character
Knowledge base: 12 character descriptions
OCEAN traits as personality cues
Reused across all frames for same character
Ablation: What Happens Without Screenplay?
Our experiment C tested three tiers: full (screenplay+pipeline), pipeline-only, and minimal (emotion label only). Result: pipeline-only still produces coherent videos — screenplay adds scene detail but isn't required.
full screenplay+pipeline (767ch)
pipeline SER/FER only (590ch)
minimal emotion label (81ch)
Module 4: Video Generation — LTX-Video 2.3 + ComfyUI
Open-source, legally licensed training data, reproducible. Three generation modes: T2V (text), I2V (image reference), A2V (audio-driven). PromptFrame → ComfyUI JSON workflow → MP4.
Three Generation Modes
T2V (Text-to-Video)
Full prompt drives everything
Character appearance in text
Primary mode for experiments
512×320 (local) / 960×544 (cloud)
Character appearance in text
Primary mode for experiments
512×320 (local) / 960×544 (cloud)
I2V (Image-to-Video)
Reference image → identity lock
Prompt describes motion only
Maintains face consistency
strength=0.7 (cloud tested)
Prompt describes motion only
Maintains face consistency
strength=0.7 (cloud tested)
A2V (Audio-to-Video)
Real speech → lip sync + expression
Demucs-separated vocal input
Prompt = visual scene only
Audio drives emotional tone
Demucs-separated vocal input
Prompt = visual scene only
Audio drives emotional tone
T2V H100
I2V (+ ref image)
A2V (+ real audio)
I2V+A2V combined
Hardware Scaling
Local RTX 5070 Ti (12GB)
GGUF Q3_K_M quantized
512×320, 49 frames (2s)
~28s/clip (warm), ~130s (cold)
ComfyUI --lowvram --reserve-vram 1.5
Max duration: ~3.4s (81f@384×256)
512×320, 49 frames (2s)
~28s/clip (warm), ~130s (cold)
ComfyUI --lowvram --reserve-vram 1.5
Max duration: ~3.4s (81f@384×256)
Cloud A40 (48GB)
FP8 quantized
768×512, 121 frames (5s)
~70-90s/clip (video only)
Max duration: ~10s (241f@768×512)
768×512, 121 frames (5s)
~70-90s/clip (video only)
Max duration: ~10s (241f@768×512)
Cloud H100 (80GB)
BF16 full precision
960×544, 121 frames (5s, with audio)
Two-Stage + LoRA + Upscaler
Max duration: ~20s (481f@960×544)
⚠ Face degrades after 14s
960×544, 121 frames (5s, with audio)
Two-Stage + LoRA + Upscaler
Max duration: ~20s (481f@960×544)
⚠ Face degrades after 14s
VRAM Safety + Experiment Design
VRAM Guard
Peak VRAM = 3GB base + 4MB × (W/32 × H/32 × F/8+1)
12GB → 512×320×49f = ~7.5GB peak ✅
12GB → 640×384×49f = ~12GB peak ❌ OOM
48GB → 768×512×241f = ~25GB peak ✅
80GB → 960×544×481f = ~65GB peak ✅
nvidia-smi polling + /free between clips
Auto-clamp: reduce frames first, then resolution
12GB → 512×320×49f = ~7.5GB peak ✅
12GB → 640×384×49f = ~12GB peak ❌ OOM
48GB → 768×512×241f = ~25GB peak ✅
80GB → 960×544×481f = ~65GB peak ✅
nvidia-smi polling + /free between clips
Auto-clamp: reduce frames first, then resolution
Multi-Seed Validation
3 seeds (42, 123, 777) per config
Old prompt scatter: 68% (unreliable)
New prompt scatter: 20% (stable)
Single-seed is insufficient for claims
Old prompt scatter: 68% (unreliable)
New prompt scatter: 20% (stable)
Single-seed is insufficient for claims
H100 Showcase (960×544, BF16, with AI-generated audio)
Proof 1: End-to-End Pipeline → Video Output
These clips are generated entirely from our prompt engine's output — pipeline analysis → 6-dimension prompt → LTX-Video 2.3. The videos prove our analysis is specific enough to be actionable.
Scarlett fury
"How proud of yourself you are!"
Prompt: physical cues from pipeline arousal=0.82
"How proud of yourself you are!"
Prompt: physical cues from pipeline arousal=0.82
Rhett farewell
"Frankly, my dear..."
Prompt: action sequence from screenplay
"Frankly, my dear..."
Prompt: action sequence from screenplay
"As God is my witness"
Prompt: wide→close push-in from arousal mapping
Prompt: wide→close push-in from arousal mapping
Proof 2: Prompt Engine Controls Different Emotions
Same character, same model, same seed — only the prompt changes. Our prompt engine generates distinct physical cues for each emotion, and LTX-Video produces visually different expressions.
angry
"jaw tightens, nostrils flare"
"jaw tightens, nostrils flare"
joy
"eyes crinkle, broad smile"
"eyes crinkle, broad smile"
sadness
"eyes glisten, lip trembles"
"eyes glisten, lip trembles"
Proof 3: Temporal Stability Limits
Same scene at increasing durations. Validates how long BF16 full-precision can maintain face quality. 14-15 seconds is the stability limit — after that, face degrades.
5s (121f)
✅ Stable, clear face
✅ Stable, clear face
10s (241f)
✅ Still stable
✅ Still stable
15s (361f)
⚠ Watch last 1-2s for degradation
⚠ Watch last 1-2s for degradation
Proof 4: Four Generation Modes (Same Scene, Same Seed)
Controlled comparison: identical scene and seed=42, only the generation mode changes. I2V locks identity from reference image. A2V drives lip sync from real audio. I2V+A2V combines both.
T2V (text only)
Baseline — text drives everything
Baseline — text drives everything
I2V (+ ref image)
Identity locked to reference photo
Identity locked to reference photo
A2V (+ real audio)
Expression driven by Demucs speech
Expression driven by Demucs speech
I2V+A2V
Identity + lip sync combined
Identity + lip sync combined
Experiment Results — 9 Key Findings
Original System Findings — Cognitive Architecture
C1. Multimodal Conflict Detection Reveals Emotional Suppression
When face says "happy" but voice says "distressed" and text says "sad" — our system flags this as emotional conflict. Across GWTW HD (3,874 utterances), the system detected 53 multimodal conflicts — moments where the character's displayed emotion contradicts their vocal/textual signals. These correspond to key dramatic moments of deception, sarcasm, or suppressed grief.
CONFLICT DETECTION — Scarlett, t=625.7s
Visual (FER)
😊
happy (0.85)
POSITIVE
Audio (SER)
😰
arousal 0.814
valence -0.312 NEGATIVE
Text (NLP)
😠
anger (0.44)
NEGATIVE
⚠ 2/3 channels disagree → CONFLICT → social smile masking internal distress
C2. OCEAN Personality Auto-Inferred from Behavioral Data
Big-5 personality traits are computed automatically from pipeline data — not manually set. Each trait maps to measurable behavioral patterns.
Scarlett O'Hara
O=0.69 (wide emotion range)
C=0.48 (low stability recovery)
E=0.79 (high arousal, vocal)
A=0.41 (more negative emotions)
N=0.72 (33% sudden transitions)
C=0.48 (low stability recovery)
E=0.79 (high arousal, vocal)
A=0.41 (more negative emotions)
N=0.72 (33% sudden transitions)
Rhett Butler
O=0.68 (diverse expression)
C=0.57 (better recovery)
E=0.72 (assertive speaker)
A=0.36 (most disagreeable)
N=0.67 (frequent shifts)
C=0.57 (better recovery)
E=0.72 (assertive speaker)
A=0.36 (most disagreeable)
N=0.67 (frequent shifts)
What the data reveals
Scarlett: highest neuroticism + lowest conscientiousness = most volatile character
Rhett: lowest agreeableness + highest conscientiousness = controlled confrontation
This matches literary analysis of GWTW without any human input
Rhett: lowest agreeableness + highest conscientiousness = controlled confrontation
This matches literary analysis of GWTW without any human input
C3. Memory System Detects Character Behavioral Patterns
Across 225 minutes of film, the memory system processed 45,528 memories (34,788 STM + 10,740 LTM). It detected 63 scene boundaries and preserved 14,876 high-arousal memories during archival. Scarlett's most common sudden transition: neutral → angry (68 times) — a pattern the system identifies as her signature behavioral response to stress.
45,528
Total memories
34,788
STM
10,740
LTM (promoted)
63
Scene boundaries
14,876
High-arousal preserved
Scarlett signature pattern: neutral → angry 68 times | Avg stability: 0.52 (volatile) | 33.1% sudden transitions
C4. White-Box Scoring Adapts to Data Quality
The 6-dimension scoring engine automatically detects when FER data is unreliable (old movie, low confidence, high neutral%) and shifts weights to SER+Text. This isn't a manual override — it's data-driven tier detection.
FER DEGRADATION AUTO-DETECTION — GWTW 1939
FER neutral ratio
72%
high → old film grain
FER avg confidence
0.41
below 0.5 threshold
Auto-detected
Tier 2: Partial
FER 25%→10% | SER 20%→30%
Result: scoring engine trusts voice + text over facial expression for this film. Modern HD → Tier 1 (full FER weight).
C5. Temporal Alignment Solves the Multi-Stream Synchronization Problem
Three data streams on different timescales must be aligned: FER (per-frame, 24fps), ASR (per-word, millisecond), SER (per-utterance, seconds). Our solution: auto-detect timestamp offsets, 3-window matching (before/during/after speech), vectorized binary search O(n log m).
4-LAYER ALIGNMENT SOLUTION
Layer 1
WhisperX wav2vec2
→ word-level ms timestamps
→ word-level ms timestamps
Layer 2
FER offset auto-detect
→ gap > 60s → correct
→ gap > 60s → correct
Layer 3
3-window matching
→ before(1.5s) + during + after(1.5s)
→ before(1.5s) + during + after(1.5s)
Layer 4
np.searchsorted O(n log m)
→ 1,544 × thousands of faces
→ 1,544 × thousands of faces
Fallbacks: SER 100ms→1.0s index | FER expand to 5s (conf 0.4) | SER range < 0.2 → auto-disable
Video Generation Findings — LTX-Video 2.3 Experiments
F1. Seed Reproducibility: Same Config = Identical Output
Three independent runs (different times, different batches) produce pixel-identical video. MD5 of raw frame data matches exactly.
Run 1
Run 2
Run 3
F2. Seed Variation: Different Seed = Different Person
seed 42
seed 123
seed 777
F3. Prompt Wording >> Sampling Parameters (4.4x)
2×2 factorial: Prompt = +66%, Parameters = +15%. Prompt matters 4.4x more.
Baseline
params +15%
prompt +66%
Both +62%
F4. Physical Cues > Abstract Labels (All 4 Emotions)
angry abstract
angry physical
sad abstract
sad physical
happy abstract
happy physical
fear abstract
fear physical
F5. Model 2.0 → 2.3: Face Quality Leap
LTX 2.0 — blurry
LTX 2.3 — clear
F6. 20s Videos Degrade After 14 Seconds
Push-in — works
Confrontation — fails after 14s
F8. Emotion Arc Stitching (FFmpeg Crossfade)
calm
angry
sad
Stitched (4.7s)
Benchmark Results
MELD (7-class, 2610 test)
Zero-shot LLM: 55.4%
Fine-tuned RoBERTa: 62.9%
SOTA: ~65%
Finding: audio degrades fusion on sitcom data
Fine-tuned RoBERTa: 62.9%
SOTA: ~65%
Finding: audio degrades fusion on sitcom data
SMIC-HS (3-class, LOSO)
Mimicking Annotation: UF1=0.7151
UAR=0.7025
Extended to 3 new datasets (not in original paper)
UAR=0.7025
Extended to 3 new datasets (not in original paper)
Video Generation
140 controlled clips
93 local + 47 cloud
Factorial + multi-seed
Human eval: emotionalai.ncnu.online/evaluate
93 local + 47 cloud
Factorial + multi-seed
Human eval: emotionalai.ncnu.online/evaluate
Micro-Expression Research — Detection & Generalization
Micro-expressions are involuntary facial movements lasting 1/25 to 1/2 second that reveal suppressed emotions. Not yet integrated into the main pipeline — research phase with successful reproduction.
4 Methods Studied (2022-2025 SOTA)
| Method | Venue | Approach | SMIC UF1 | Status |
|---|---|---|---|---|
| Mimicking Annotation | ACM MM 2022 | Optical Flow + ResNet50 + AU contrastive | 0.7151 | Extended to new datasets |
| Micron-BERT | CVPR 2023 | ViT + Diagonal Micro-Attention | 0.6290 | Partial |
| MOL | TPAMI 2025 | Multi-task (ME+Flow+Landmark) | 0.2186 | Failed |
| FDP | TOMM 2025 | Dynamic Image + Fine-Grained | N/A | Failed |
Key insight: Models using standard backbones (ImageNet ResNet50) succeed. Models requiring custom pretraining (Aff-Wild2) fail without the weights. Reproducibility remains a major challenge.
MOL mode collapse root cause confirmed: Even after fixing ALL engineering issues (raw 640×480 images, FlowNet on CUDA, 700 steps), MOL still mode collapses — 100% predicting majority class. GitHub Issue #2 confirms: multiple users report same problem, author never replied. The 44M parameter multi-task model × 164 samples = inevitable collapse without Aff-Wild2 pretraining. This is a fundamental method limitation, not an engineering problem.
Mimicking Annotation — Three Dataset Results
Successfully validated across 3 independent datasets with consistent performance above random baseline (2.1x-3.7x). All use identical hyperparameters — no per-dataset tuning.
| Dataset | Classes | Samples | Subjects | UF1 | UAR | vs Random |
|---|---|---|---|---|---|---|
| SMIC-HS | 3 | 164 | 16 | 0.7151 | 0.7025 | 2.1x |
| 4DME (MTCNN) | 4 | 220 | 42 | 0.6844 | 0.6895 | 2.7x |
| MMEW | 7 | 300 | 30 | 0.4838 | 0.5284 | 3.7x |
Comparison with SOTA Methods
SOTA methods are dataset-specific with tuned hyperparameters. Our method uses unified hyperparameters across all datasets — different research goals. Despite this, we are competitive.
SMIC-HS (3-class)
| Method | UF1 |
|---|---|
| JGULF (2023) | 0.8112 |
| Micron-BERT (2023) | ~0.80 |
| Ours (unified) | 0.7151 |
MMEW (7-class)
| Method | UF1 |
|---|---|
| TRDI+MIDI+AFN (2025) | 0.5579† |
| FAMNet (2025) | 0.4342 |
| Ours (unified) | 0.4838 ✓ |
† 6-class eval (excl. Others), not directly comparable
Key analysis: As class count increases (3→4→7), absolute UF1 decreases (0.71→0.68→0.48), but the relative advantage over random baseline increases (2.1×→2.7×→3.7×) — the method shows stronger relative performance on harder tasks. On MMEW, we outperform FAMNet (0.4838 vs 0.4342) with zero tuning. Our contribution is not chasing SOTA on one dataset, but demonstrating a unified, transferable framework with practical deployment value.
SMIC-HS Results (3-class, LOSO 16-fold)
Three columns per sample: Apex Frame → Optical Flow (TVL1 onset-apex) → Attention Map. Green = correct. Red = incorrect.

SMIC-HS: 9 samples, UF1 = 0.7151
MMEW Results (7-class)
Harder benchmark. Row 4: model predicts happiness instead of anger — but attention correctly focuses on mouth (AU23+AU24). Error from ambiguous optical flow, not wrong attention.
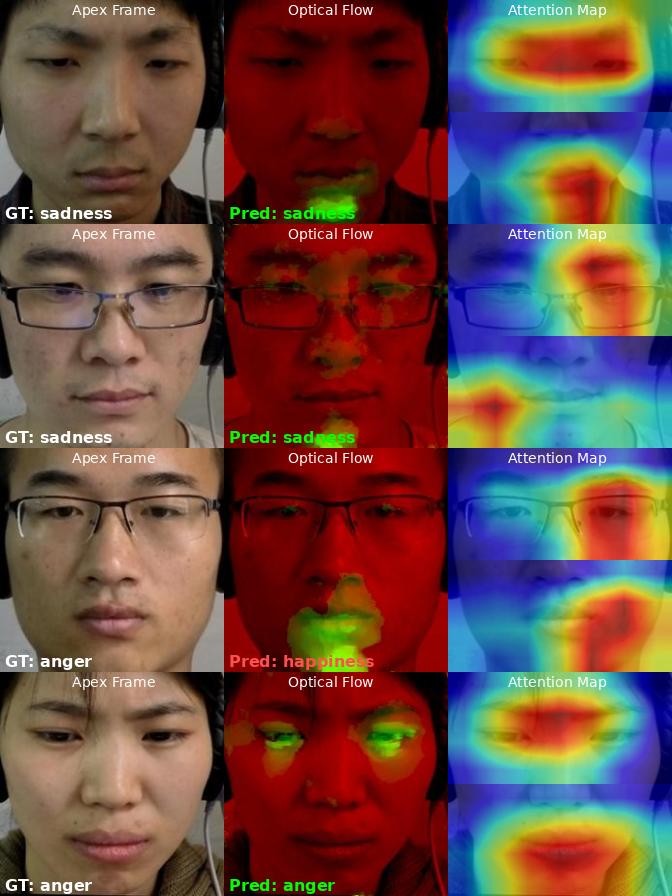
MMEW: sadness correct (rows 1-2), anger misclassified (row 4)
4DME Results (4-class, MTCNN cropped)
Grayscale video dataset (220 clips, 42 subjects). MTCNN face cropping improved UF1 from 0.6309 → 0.6844 (+5%). Negative: attention on brow+mouth corners. Surprise: attention on upper eye area (brow raise). Positive: attention on mouth region.

4DME (MTCNN cropped): 12 samples — UF1 = 0.6844 (2.7x random)
Integration Plan
Micro-expression detection will become the 5th perception channel, adding sub-second emotional leakage detection to the existing FER/SER/Text pipeline.
🎬
Video 24fps
→
Onset/Apex
Pair detection
Sliding window
Sliding window
→
TVL1 Optical Flow
Compute motion
between frames
between frames
→
ResNet50
Dual-stream
eye + mouth
eye + mouth
→
Micro Label
+ confidence
Channel 1
FER (face)
Channel 2
SER (voice)
Channel 3
Text (NLP)
Channel 4
Listener
Channel 5
Micro-expr
→
Fusion
Weighted voting
Conflict Example: macro(FER) = 😊 happy + micro = 😤 disgust → Suppression Detected (multi-evidence confirmed)